

A recent patent publication disclosed Microsoft’s new multi-talker speech recognizer that can identify words spoken by multiple people at the same time. Until now, it has been hard to program computers to accurately identify sounds of multiple people. However, now you and your friends can speak to Cortana (a virtual assistant by Microsoft) at the same time and Cortana will recognize each statement from you and your friends separately. With Microsoft’s multi-talker speech recognizer, an audible speech from multiple people will be recognized as precisely and accurately as recognized for an audible speech from a single person.
Microsoft’s multi-talker speech recognizer consists of a microphone that will collect a mixed speech from multiple users (talkers). There can be more than one microphone that can collect the audio signal from more than one users. The mixed speech is then processed by a PIT separator for separating the audio signal into multiple speeches of the multiple users (talkers). The PIT separator employs permutation invariant training (PIT) of deep learning models for speech separation such that an error in an output may be as minimum as possible.
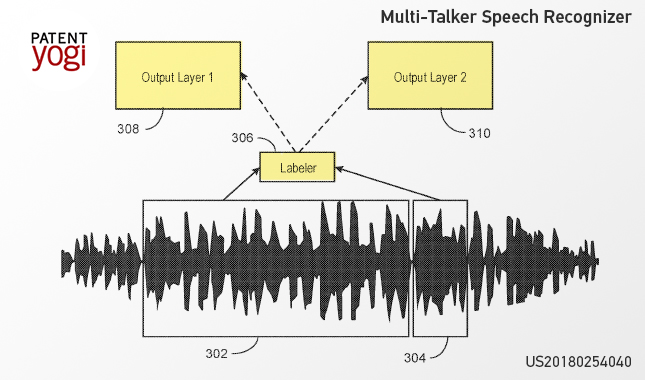
Further, the permutation invariant training (PIT) of deep learning may separate the mixed speech based on an utterance criterion. The utterance criterion allows the PIT separator to assign and/or separate the mixed speech based on an utterance (such as words, vocal sound, and/or other non-linguistic sounds) in the mixed speech. For example, figure 2, shows a simple case where there are two utterances, utterance 1 (302) and utterance 2 (304) that will be separated and labeled at a labeler (306). Further, the outputs may be labeled as either output layer 1 or output layer 2 for two speakers (say speaker 1 and speaker 2).
Patent Information
Publication Number: US20180254040A1
Patent Title: Multi-talker speech recognizer
Publication date: 2018-09-06
Filing date: 2017-05-23
Inventors: James Droppo, Xuedong Huang, Dong Yu
Original Assignee: Microsoft Technology Licensing LLC
US20180254040A1