
Facebook is the most popular social network worldwide. In the second quarter of 2016, Facebook reached 1.71 billion monthly active users. It has been predicted many times in the past that Facebook is going to face challenges in growing its number of users. However, Facebook has been able to beat such predications with innovations and grow consistently over a period of time.
In fact, Facebook has a special team for finding new ways to grow. The growth team formed in late 2007 and it is performing well since then.
A new patent application from Facebook indicates that Facebook plans to go ultra-local to further increase its penetration across the world. Language poses a significant challenge when it comes to reaching out to a global audience.

While communication across the many different languages used around the world is a particular challenge, several types of language modules, such as language classifiers, language models, and machine translation engines, have already been created to address this concern. These language modules enable “content items,” which can be any item containing language including text, images, audio, video, or other multi-media, to be quickly classified, translated, sorted, read aloud, and otherwise used based on the semantics of the content item. However, these language models do not account for differences in dialect used within particular languages. For example, traditional speech recognition and machine translation systems for Arabic focus on Modern Standard Arabic (MSA), and do not account for other Arabic dialects, which can differ from MSA lexically, syntactically, morphologically, and phonologically. Such speech recognition and machine translation systems are not able to adequately recognize or translate content items to or from non-MSA dialects.
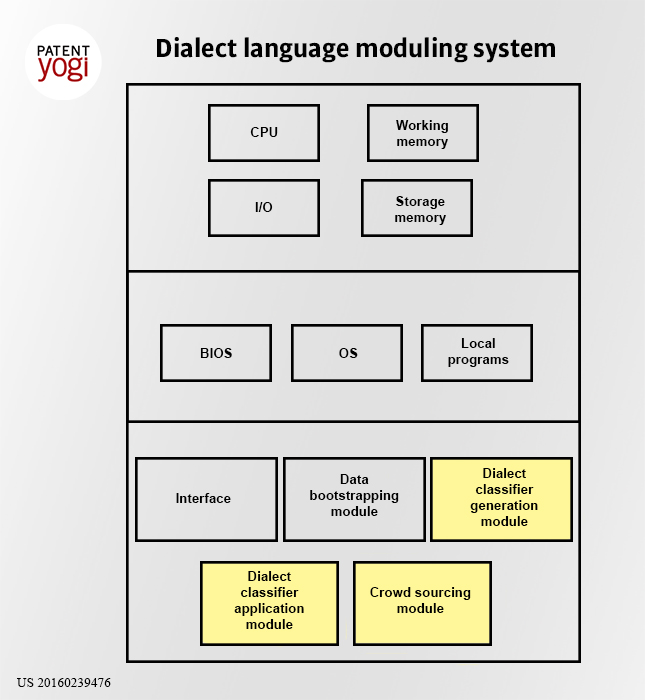
Facebook has developed language dialect technology that creates and tunes classifiers for language dialects and generates dialect-specific language modules. The language dialect technology obtains initial bootstrap training data and builds a dialect classification engine (e.g., a neural network or other classifier technologies) for a selected dialect based on the initial bootstrap training data.
The language dialect technology uses the dialect classification engine to create language modules, including machine translation engines, speech recognition systems, language classifiers, and language models, each of which account for differences in dialects. For example, variants of the same language (e.g., American English versus British English), can use different meanings of the same word, non-standard phrases (e.g., slang), etc. The word “lift,” for example, can mean “move upward” among speakers of American English (as that word is commonly used in America), whereas it can mean “elevator” in content items created by English speakers with a British dialect. Depending on the dialect classification assigned to a content item by a dialect classification component, the phrase, “press the button for the lift,” can be translated into an equivalent of either “press the button for the elevator” or “press the button to go up.” Similarly, the machine translation engine can use the dialect-specific language model to translate a content item from English to a particular dialect of Arabic.
This technology will make people feel “at home” when they use Facebook. This will help Facebook in increasing the number of users and also the time they spend on the platform.
Publication number: US 20160239476
Patent Title: Machine Learning Dialect Identification
Publication date: 18 Aug, 2016
Filing date: 13 Feb, 2015
Inventors: Fei Huang;
Original Assignee: Facebook, Inc.